



英特尔Xeon Phi的x86微异构技术解析
两年前,天河1A在超级计算机500强榜单上称雄,将中国第一次带到了高性能计算领域的巅峰,随着天河1A的崛起,混合加速架构在超大规模并行计算的应用也一同开始觉醒。两年后,架构革新的天河2号上演了王者归来的好戏,同时也将英特尔Xeon Phi协处理器带入了我们的视线。超级计算机为何钟爱加速卡?Xeon Phi与NVIDIA Tesla有何不同?它会成为下一轮变革的起点吗?

从零崛起的异构加速市场
在2007年6月以前,加速卡对于超级计算机来说还是只闻其声不见其人的概念产品,在当时的超级计算机五百强榜单上,使用加速卡的系统数量还停留在0,所有的系统都采用了暴力堆彻CPU核心的架构。在一家名不见经传、雇员人数尚不到10人的英国小公司Clear Speed推动下,加速卡第一次进入了超级计算机市场。业界巨头NVIDIA随后跟进将前浪Clear Speed拍死在沙滩上,高性能计算市场迎来第一轮井喷,只花了5年时间榜单上就已有超过6 0台超级计算机转向异构体系。
异构体系迅速收获众多认可,原因是多方面的,其中的重要一环,便是加速卡具备传统CPU无法比拟的优势,分析2011年登顶的天河一号以及被它击败的美洲虎就不难找出答案。美洲虎基于CrayXT5架构,是一个由纯CPU组建的超级计算机,CPU核心数目接近22.5万个,虽然美洲虎成功地在快速洗牌的五百强榜单前三甲停留了两年之久,但是它的能耗也高达700万瓦特,为它供电、冷却都要花费不菲开销,而天河一号则是CPU+GPU的异构体系,CPU核心数目只有18.6万个,但却搭配了七千多张Tesla 2050加速卡,运算速度领先美洲虎42%,但是功耗却只有400万瓦特。如果天河一号放弃采用异构而继续坚守传统纯CPU架构的话,要达到同等性能,核心数量需超过30万,这意味着两倍的占地面积和四倍的功耗,等同于更大的运营开销。对比之下可以发现,异构系统能够以更少的核心数量,实现更强大的运算能力以及更高的能耗效率,看到如此显著的优势,就不难理解为何有越来越多的超级计算机采用异构体系,开始引入加速卡和协处理器了。

Top500榜单中使用混合加速架构的系统数量
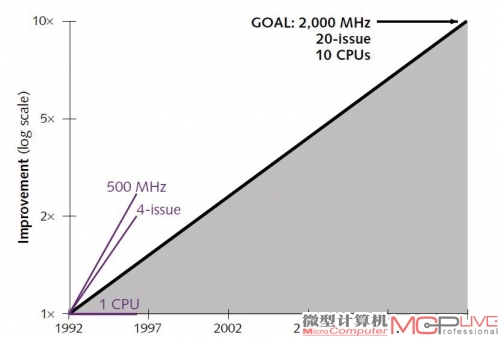
DEC公司于1992年所期望的CPU发展进程,当时预期2017年会出现20发射的CPU。

Netburst架构处理器的演进验证了功耗墙的存在
CPU瓶颈的前车之鉴
现代高性能CPU架构的技术,许多都脱胎于上世纪八九十年代、甚至是六七十年代的研究,经过了充足的时间沉淀,是一个发展较为成熟的领域,在众多高性能CPU架构相互厮杀的战场上,加速卡何以能够后发制人抢得一席之地?这是一个值得说道的话题。翻阅上世纪八十年代末期至九十年代中期的资料便不难发现,当时学术界与工业界热衷于具备宽发射、长流水、乱序执行、分支预测能力的CPU,认定这将是未来的发展方向,这些技术的研究热火朝天,有的学者甚至乐观地展望,未来将出现每周期15发射以上的惊人前端发射宽度。这样激进的宽发射CPU当然并未成为现实,作为对比,Haswell架构的发射宽度为4(因为可以发射融合微指令,所以实际等效发射宽度稍高),安腾2架构在编译器调度的帮助下也只能做到12发射。这种乐观预期的存在很好地反映了当年的时代局限,九十年代微架构设计的主流观点是,若想提高计算速度,加强CPU核心的执行能力是重点。在这样的指导思想下,著名的Intel P6微架构诞生了,双发射+长流水+乱序执行+分支预测一应俱全,核心频率越来越高,逻辑越来越复杂,直至Net Burst架构的高频奔腾4芯片沉沙折戟。
重新审视当时的失败原因,主要有两个。其一,功耗墙(power wall)。用以加强CPU核心执行能力的这些技术将大幅推高功耗,以乱序执行为例,每一条指令的发射和执行都需要经过一整套逻辑的检查以确保流程正确,并占用额外的寄存器,这意味着每一条指令的执行都需要更多功耗。这种愈发激进的CPU设计在Netburst架构时代迎来顶峰,随后狠狠地撞上了功耗墙。前英特尔副总裁Patrick Gelsinger曾在2001年的国际固态电子电路会议上发表主题演讲,警告说CPU的功耗密度如果继续提高,不出几年就将摆脱现有一切冷却手段的束缚,彻底失去控制。更加不妙的是,仿真结果揭示,即便倾尽全力,给定无限多的芯片面积预算去设计一个发射宽度远超当下,配备极强的乱序执行能力和分支预测器的CPU,其整数指令发射能力也不过提高区区几倍,这样的设计思路下,改进潜力已经不大。
其二,存储墙(memory wall)。愈发激进的CPU设计将CPU核心的执行速度提得很高,存储器系统已经越来越力不从心。提供足够大的存储容量和提供足够快的响应速度在本质上是矛盾的,冯·诺依曼早在1945年就断言容量和速度的需求无法同时满足,这位大师级人物不幸再度言中,存储器系统越来越难以用足够快的速度交付和接受指令与数据,引发了架构设计者们的担忧。DEC公司Alpha架构的首席架构师理查德·赛特斯在1996年的《微处理器报告》上撰写了一篇标题为《瓶颈在内存,愚蠢!》的惊世雄文,据他披露的测试结果,当时出色的乱序超标量处理器若是管线填满,理论上每周期可以完成两条左右的指令,而实际执行时每四到五个周期才会有一条指令完成,落差几乎达到十倍,花费学术界与工业界无数心血研究测试的超标量乱序执行并未如想象中那样强大,优势几成泡影。这项测试非常有力地证明,整个执行模式存在极其严重的瓶颈,制约了整个CPU的性能,而这个瓶颈就在于存储访问速度。花费如此大的精力设计的高性能CPU,却花费了90%的时间等待存储器系统的响应,这不能不说是一种莫大的讽刺。赛特斯不无悲观地认为,在未来的处理器微架构设计中,存储器系统将成为唯一的关键因素。
面对这些挑战,业内较有远见的架构师已经开始讨论另一种全新的架构设计方式,他们设想抛弃高能耗的复杂乱序执行核心,转而采用设计精巧简单、功耗较低的小核心,将设计重点放在提高对存储器系统的延迟容忍上,依靠多核心多线程并行执行来躲避存储器系统的延迟—这便是后来NVIDIAGPGPU的核心设计理念之一。无独有偶,英特尔XeonPhi也有相同的考虑。基于这种全新的设计思路,异构加速卡才得以异军突起。
CPU与GPU的异构潜力
计算机上运行的程序种类繁多,有的程序代码包含大量分支(例如编译器、人工智能、电路真值表生成),需要CPU拥有强大的分支预测器,有的程序代码频繁取用数组元素(例如矩阵计算),对CPU的存储访问能力提出了很高的要求。设计一个万能型的CPU,要求它运行所有种类的代码都能达到快速度,这是极其困难的,但是如果能够区分程序类型,针对性地设计多种处理单元,令其分工合作,则有可能满足所有需求,这被称为异构计算。

架构包含16组SIMD处理单元

PA-8700微处理器,蓝色大块是数据缓存,绿色和橙色大块是指令缓存及其标记位,计算单元龟缩在右上角

近20年前的P54C架构的优势在于流水线短、核心简单

Xeon Phi内部拥有数十个精简的P54C架构核心
在讲述GPGPU的运算优势之前,我们先来看看初中数学水平的简单向量加法。考虑两个宽度为16 的向量相加,{1,2,3,…,15,16}+{1,2,3,…,15,16}={2,4,6,…,30,32},不难发现,其中每组对应数字的相加,相互之间并不干扰,不存在相关性,而且没有分支,可以完美地实现并行。只需让一条加法指令同时控制十六条逻辑通路,引导十六组寄存器中的数据进入ALU,再同时写回寄存器,就可以并行做完这个宽度为16的向量加法,用体系结构的术语来说,这被称为宽度为16的SIMD执行(单指令多数据)。
研究显示,与此例类似的向量计算代码经常出现在某些特定种类的程序中(例如图像编解码)。因此,这种能够一次处理多组数据的SIMD处理单元就可以考虑作为GPGPU的基本构建模块。以NVIDIAFermi架构的GTX 480为例,它内部的SIMD处理单元宽度为16,整个核心拥有16个这样的处理单元,一个时钟周期就能完成256FLOPS的运算量,这个并行计算的宽度是惊人的,但是强大的并行能力背后需要寄存器或者存储器系统的支持。如果每个操作数都由内存提供,那么每进行一次单精度计算都需要内存系统提供2KB数据,显然这是难以达到的,如此大的存储访问压力需要使用其他技术进行分摊。
因此,GPGPU通常具备数量庞大的通用寄存器组,尽量使数据保存在本地,同时每个SIMD处理单元都具备多线程的硬件支持,例如Fermi的每个SIMD内部都设立了一个包含48线程的调度表,能够在当前线程发生存储访问停顿时迅速切换至其他线程,通过多个线程的重叠执行来隐藏存储访问延迟。除此之外,GPGPU的内存控制器也支持Gather-Scatter(分散-集中)操作,能够应对部分不规则的内存位置访问,对接的内存系统也是经过特别设计以实现更高带宽。从图中可以看出,GPGPU核心内部的缓存所占面积也很小,绝大部分芯片面积都用来构建逻辑运算单元和数据通路。相较之下,CPU则依靠更大的缓存来弥补内存缺憾,缓存所占芯片面积达到50%是常事,历史上甚至出现过HPPA-8700这样的奇葩架构,缓存所占面积几乎达到四分之三。
经过这样设计的GPGPU架构,其控制逻辑相对简单,一条指令便可以控制极宽的数据通路,而数据通路可以按照需求进行关闭,缩减功耗,因此这种架构能够带来更好的能耗表现,这便是架构设计师们对功耗墙问题所做的应对措施之一。再来看访存墙,GPGPU的线程并行度很高,来回切换线程的做法能更好地容忍内存延迟,但是对内存带宽需求更高,而且要求存储访问更加局部化。当计算任务的相关性很弱,几乎不存在分支,且内存访问模式比较规律的时候,GPGPU能够以更快的速度执行完毕,这部分优势是GPGPU截然不同的设计思路所带来的,也是传统CPU难以企及的,在GPGPU上实现较高计算加速比的通常就是这类程序。但是GPGPU也并非万能,它处理分支的能力很弱,目前大多依靠谓词执行,如果让GPGPU来处理分支较多的程序,SIMD单元就会在各种指令路径间来回切换,效率大打折扣。例如,给定一个宽度为16的向量,根据每个数字的奇偶性来决定执行路径,偶数则执行乘法,奇数则执行除法,那么就无法再依靠单一指令指挥整个向量数据流了,而这种工作在CPU上却得心应手。此外,若计算任务出现较强的相关性,程序员就很难编写并行化的代码,这部分任务也很难在GPGPU上执行。因此,可以预见CPU+GPGPU需要在以后的时间里分工合作,让CPU凭借强大的分支预测和快速串行执行能力来处理串行化代码,而GPGPU处理并行化的代码,以这种异构计算的方式实现更高的效率,NVIDIA的CUDA编程语言和GPGPU执行架构便是基于这样的思路设计,那么作为业界巨头的英特尔,又是如何做的呢?
P54C架构,从二十年前的草图起步
既然以P6架构开始的宽发射乱序推测执行架构已经遭遇瓶颈,并且被证明不再适合多核扩展,英特尔的工程师们便选择了P6架构的前代P54C架构作为设计蓝本。乍看之下,这是一个完稿于1995年以前的老旧架构,距今已有近20年。P54C是短流水、顺序执行的简单核心,从性能来看,它与P6相去甚远,可以说是落后了一个时代,甚至没有进入竞技场进行比试的资格。英特尔选择这个架构是不是败笔?
个架构是不是败笔?答案很明确:这非但不是败笔,反倒是一个非常英明的设计决策。英特尔需要一个新的架构与NVIDIA等公司的GPGPU竞争,从本质上来说,这个架构需要容纳数目相当多的核心以提供足够的并行能力,它所需要的技术已经与当下的四核、八核等多核心架构有所不同,因而应该称之为众核架构。在这个众核架构下,选择什么样的核心作为单一基础构建模块便是首要问题。
如果英特尔选择P6或者是更加复杂的高性能核心来组建众核,能耗效率就会不可避免地降低。复杂的高性能x86核心执行串行指令的速度的确很快,但是每一条指令的能耗开销也更大,到了大规模并行的众核时代,如果每条指令的开销还与串行核心一样,这个众核系统就无法交出满意的功耗成绩单。在这一点上,Xeon Phi的设计无疑是果断而正确的,它并非为单线程性能而生,无法将并行的代码交给高性能CPU去完成,推高单线程性能的技术在Xeon Phi身上没有多大用处,它的设计目标是支持多线程并行的众核架构,以并行宽度换取速度。我们不难看出,英特尔也与NVIDIA一样,选择走上了多核心多线程的道路,P54C被加上了硬件四路线程支持,每个核心能够在四个线程间来回切换执行,以重叠存储访问延迟。对于要求吞吐量而不是单线程响应速度的大规模并行计算而言,这是方向正确的一步,但是步幅是否够大,仍不明了。P54C核心目前仅有四线程并行,并且不支持同一个线程在相邻的两个时钟周期内连续发射指令,这就意味着,P54C核心必须喂给至少两个线程才能连续不断地发射指令,四个线程提供的调度空间是否足够隐藏延迟,我们并不清楚。
再看核心内部,P54C为双发射架构,它的执行流水线有两条,为保留奔腾时代的传统,标号分别为U和V。挂载在U流水上的便是XeonPhi架构赖以为生的SIMD执行单元,以及为了提供兼容性而设置的x87浮点处理单元,挂在V流水线上的是负责标量操作的逻辑运算单元,从这一结构看,P54C的确仍然保留了CPU核心的特征,但是又有所不同。传统高性能CPU会在流水线中插入一些缓冲区,以保证某一区域的停顿不会波及整条流水线,这对于单线程性能很重要,但是Xeon Phi架构中的P54C核心则抛弃了这项特征,流水线一旦停顿,则牵一发而动全身。显然这也是为了削减核心复杂度,降低功耗所做的牺牲。几乎退回“石器时代”的串行能力换来了并行能力的突破性进步,U流水下的S IMD执行单元宽度达到了史无前例的512位,是Ivy Bridge的两倍。一个单精度浮点数占据32位宽度,因此这个SIMD单元能够一次执行16个单精度浮点计算。这是有史以来宽的CPU SIMD单元,并且双精度浮点计算速度也达到了单精度的二分之一。这对于部分寄望于使用Xeon Phi来进行科学计算的人来说是个好消息:Intel已经做到半速双精度浮点执行,与NVIDIAFermi架构齐平。
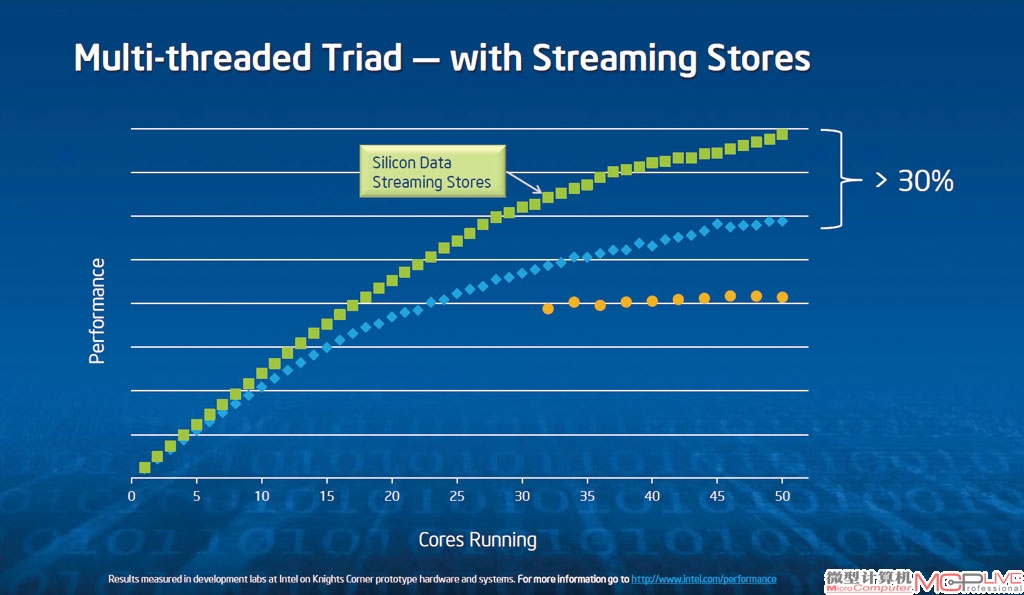
时,若挂载超过32个核心,系统的性能增长就开始停滞;如果使用两条地址通道和消息通道,就可以一直扩展到超过50个核心。")
只有一条地址通道和消息通道(橙色点)时,若挂载超过32个核心,系统的性能增长就开始停滞;如果使用两条地址通道和消息通道,就可以一直扩展到超过50个核心。
来自二十年前的P54C架构实现了一步登天。双精度数字占据的存储空间为64位,比单精度多一倍,因此若使用同样的执行资源,双精度计算的速度多只有单精度的一半,但是即便做到半速执行也并不容易,作为对比,GT200的双精度计算速度只有单精度的八分之一,RV870也只有五分之一。NVIDIA和AMD为了抢夺科学计算市场都逐步完善了双精度的半速执行,现在我们看到英特尔也开始强化这方面的表现。单精度浮点的计算精度相对较低,进行一些数值模拟时有更大可能出现误差,如果把代码转变成结果更加精确的双精度执行,在此前的架构上速度就会大幅度降低,因此提高双精度浮点的计算速度是针对科学计算市场的一项重大改进。
除此之外,这个SIMD单元也支持单周期浮点乘加指令,支持向量执行中非常重要的gatte rscatter操作,使用谓词寄存器来处理向量中的条件分支,从这些特性上来看,P54C的改进颇有些向GPGPU靠拢的意味。改进的P54C核心已经具备了GPGPU内部SIMD处理单元的一些特征,英特尔称之为“微异构”,并非没有道理。我们很高兴地看到,作为CPU业界的巨头,英特尔并未固步自封,仍在尝试借鉴GPGPU体系结构中的精华并将之引入自己的众核架构。
缓存与互联,面向未来众核时代
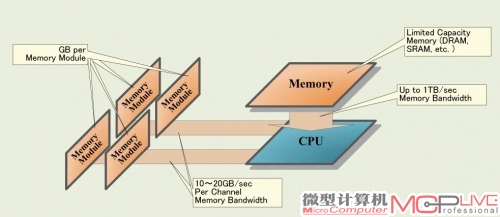
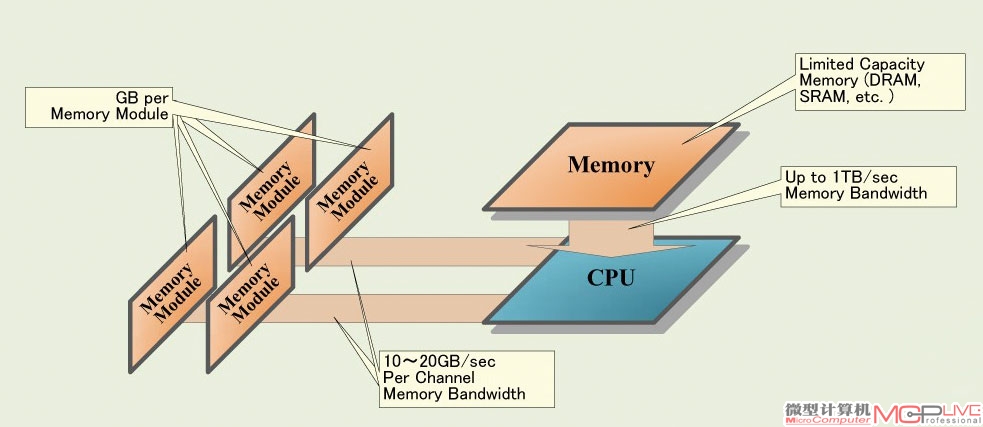
对比GPGPU,Xeon Phi这种基于简单CPU的众核架构对缓存更加重视。每个P54C核心内部都具备32KB的一级指令缓存和32KB一级数据缓存,以及512KB二级缓存。作为对比,NVIDIA Kepler架构的每一个SMX内建4个SIMD处理单元,每个处理单元的宽度允许48个单精度操作,整个SMX允许192个单精度操作,六倍于P54C的宽度,但是这样一个SMX单元才能共享64KB的片上缓存,48K B限制用途的只读常数缓存,以及1.5MB的二级缓存。对缓存的注重并不仅仅来自于对性能的需求,与内存系统在大规模并行计算的前提下,更大的缓存也能够帮助削减功耗。在天河2号这样规模的超级计算机里面,计算能力是很廉价的,真正昂贵的是大规模的数据存储和传输。在同样的功耗限制下传递数据,缓存能够提供更高的带宽。
设计一个双核心到八核心的多核架构,与设计一个60核心的众核架构,需要注重的技术细节有所不同。60核心的架构不是简单堆砌核心就能搭建起来。在少量核心之间切割任务、分工合作、互通消息,是一件相对简单的事情,但是当参与工作的核心数量达到Xeon Phi架构的量级时,性质就不一样了。

从左到右依次为内存、二级缓存和一级缓存,单位功耗下提供的带宽缓存完胜。

Xeon Phi的核心互联网络,由数据通道、地址通道和消息通道组成,双向三通道互联。
想象一下这样的场景:一个多核心处理器接到了计算任务,第一个处理核心将数据复制入自己的内部独立缓存开始处理,完成自己的工作之后,将新结果写回自己的内部独立缓存。第二个核心紧跟着开始自己的计算,这时候问题就来了,刚刚完成的计算结果还保存在第一个核心内部的独立缓存上,第二个核心从内存中取用的数据没有得到来自第一个核心的更新通知,它不能再使用已经失效的旧数据进行计算。新旧数据同时存在时,在多个核心之间保持同步、及时更新数据的过程,被称为保持缓存的一致性。这是影响众核架构是否具备可扩展性的关键因素。显然,第一个核心已经修改的数据必须以某种方式通知其他核心,以确保其后的计算都能及时使用新数据。一种基础架构是,使用总线连接所有处理核心,让修改了数据的处理核心通过总线向其他核心进行广播,其他核心收到总线通知后就将自己缓存中存放的旧数据抛弃,当需要使用新数据时,再通过总线发送广播请求,拥有新数据的核心来应答这个请求。当核心数目较少时,这种监听式架构因为简便易行,容易实现而受到青睐。但是对于Xeon Phi这样的众核架构,使用广播-监听总线的做法就完全不可接受,大量的核心抢用总线会形成严重的竞争,若是在众核架构上部署广播-监听总线来保持缓存一致性,那么它就得具备数百GB/s的惊人带宽,远超当前任何一种芯片内部总线互联系统的承受能力。Xeon Phi必须采用新的互联方式,并且尝试减少泛滥的一致性通信,以降低互联系统的压力,才能真正拥抱众核。
为了达到这样的效果,Xeon Phi的核心之间由环状、双向、三通道的互联系统连接。这三条通道分别为数据通道、地址通道和消息通道。为了在互联系统上一次性传递整个缓存数据块,数据通道达到了惊人的64字节、256位的宽度,与一级缓存的数据块大小吻合,Intel的工程师们为了增强众核架构的可扩展能力,所做的投资可以说是不惜血本。整个缓存一致性协议基于可扩展能力较强的目录系统构建,在每个核心的二级缓存上都额外设立了一个目录,指示其他核心缓存中的数据保存情况。通过探查这个目录,就可以得知其他核心中的数据是否一致,是否能够读写,而目录中的信息依据存储访问动作而在互联系统上相互做出点对点式定向更新,这样一来就大幅减少了无谓的广播消息传递,使得整个互联系统能够挂载更多核心。
即便采用了目录系统,60个核心之间为了保持缓存一致性所带来的通信负担还是太大,每次二级缓存缺失时,计算核心都会在地址通道上生成一个请求,探查目录,如果目录并未指出哪一个核心拥有数据,核心就会再度生成第二个地址,向内存系统请求数据。这样一来,为了获取一个数据块,地址线承受了两倍的压力。仿真结果显示,如果只采用一个地址通道和一个数据通道,那么众核架构增长到超过32个核心时,性能就开始停滞。而加一条地址通道和一个数据通道之后,性能还可以提高,以50个核心为基准,增加通道后的性能可以提升40%,再加上流式储存的优化,在面对某些数组访问较为密集的程序时还可以提升30%。
未来异构,花落谁家?
英特尔XeonPhi众核架构在此之前遭受众多非议,此次助力天河2号登顶Top500榜单可以说是扬眉吐气。众核架构已经证明,自己不但能在超级计算机市场上立足,而且还具备与顶尖级GPU加速系统一决雌雄的能力。但是若要它达到与GPGPU一样的应用规模,可能还需要一段时间才行。抛开纯架构层面的优劣不谈,基于简单x86核心设计众核架构,相对于GPGPU来说有一个显著优点,便是x86的前向兼容性。基于GPGPU的编程需要程序员们额外学习CUDA或者Open CL等通用计算语言,提高了开发门槛;而x86的前向兼容性则意味着此前能够在x86架构上运行的程序也能够在Xeon Phi上运行,或者经过重新编译后运行。这实在是一个致命的诱惑,这意味着,即便GPGPU在基础架构上相对Xeon Phi能领先些许,程序员们也会被x86的大旗给吸引到Xeon Phi的阵营中来,使得GPGPU曲高和寡。愿景虽好,但英特尔试图以这份兼容性作为武器攻击GPGPU,还需跨越一道鸿沟:串行代码的并行化。这是一个世界级难题,SIMD 架构虽然好处多多,但在传统上,SIMD指令大都需要负责性能调优的程序员在代码中手动内联,开发成本较高。编译器只能将比较简单的串行代码实现并行化,尚无力替代人脑。NVIDIA甚至声称,不论现在还是将来,都不可能出现这样一个神奇的编译器,将原本串行的代码自动优化成适合Xeon Phi的并行形式,因此x86前向兼容并不意味着应用可以无缝迁移。程序员永远需要付出劳动,才能编写好的并行代码。GPGPU目前倾向于程序员手动管理缓存,手动处理各个SIMD单元之间可能出现的存储访问交叉,甚至连寄存器压力的优化这种相当底层的细节都暴露给了程序员,程序员能够直接控制许多硬件资源,但是开发难度也较大。Xeon Phi众核架构则实现了硬件缓存一致的存储器系统,解放了程序员管理缓存的压力,但就目前的技术水平来看,这条路还没有辉煌到能够全自动地进行代码并行化。因此从本质上来说,Xeon Phi与GPGPU的较量并非仅仅在于架构上,也在于设计哲学上。两个持有不同价值观的阵营所进行的较量,可能需要相当长的一段时间才能决出胜负。


{kind=link}
{kind=link}